

Blueprint to Bytes: Building and Consuming a GraphQL API
Unlocking the Power of GraphQL with Spring Boot


The goal of this article is to show the setup and usage of a GraphQL API in our bookstore application to enable interaction with the user. This also reflects on our CQRS Design as we have Mutations that are Commands and Queries to fetch data.
I actually learned GraphQL by working on a NestJS backend a few years ago at a different job. I really liked the technology and found it worked like a charm. Later, for personal projects like a text-based browser game (which I sadly never finished), I started using Spring Boot with GraphQL. I really liked the integration, and that's why I wanted to share this with you.
🙌 Catch Up
Previously in this series, we explored Couchbase and Database Migrations.

👋 Introduction to GraphQL
APIs (Application Programming interfaces) are essential for modern applications. They enable communication between different systems and components. We have already seen Messaging APIs in our series for loose coupling and better scalability and now we have a more user facing API.
You may have heard of REST (Representational State Transfer), a paradigm for for the architecture of web services. The service is treated as a resource and can be manipulated by HTTP methods like GET or POST with a more or less strict design. POST for example is intended to be not idempotent while PUT should be idempotent, that means always delivering the same response. REST APIs are stateless, so each request should contain the information necessary so that the server can respond independently.
GraphQL is a modern alternative developed by Meta to mitigate some of the issues of traditional REST APIs. You often need several endpoints and operations to fetch the necessary data while GraphQL offers one endpoint where the client requests the data needed. This brings more efficiency and reduces unnecessary traffic over the wire.

Benefits of using GraphQL:
Efficient Queries as the client specifies the data needed
Strong typing with the GraphQL schema, leads to early detection of error
Easy evolution by changing the schema without breaking existing queries
🖇 Integrating a GraphQL Server for Our Bookstore Application
Setting up a GraphQL server allows users to easily fetch the necessary data. In this guide, we'll demonstrate how to set up a GraphQL server for a Spring Boot application and integrate it into our Bookstore Application.
Gradle Dependencies
To start with GraphQL, you need the following Gradle dependencies:

Defining the Schema
Next, define the schemas for your GraphQL API. The schema explicitly defines the types of data available in the API, including their fields and relationships, enhancing type safety. We also specify the types of operations with queries and mutations. The schema file serves as a self-documenting mechanism.
Place a .graphqls file on the classpath under src/main/resources/graphql. Inside this file, define your types, queries, and mutations.

Spring GraphQL Controller
The next step is to create our Spring Controller with the appropriate annotations. We use @QueryMapping, @MutationMapping, and @Argument instead of the usual @RestController.
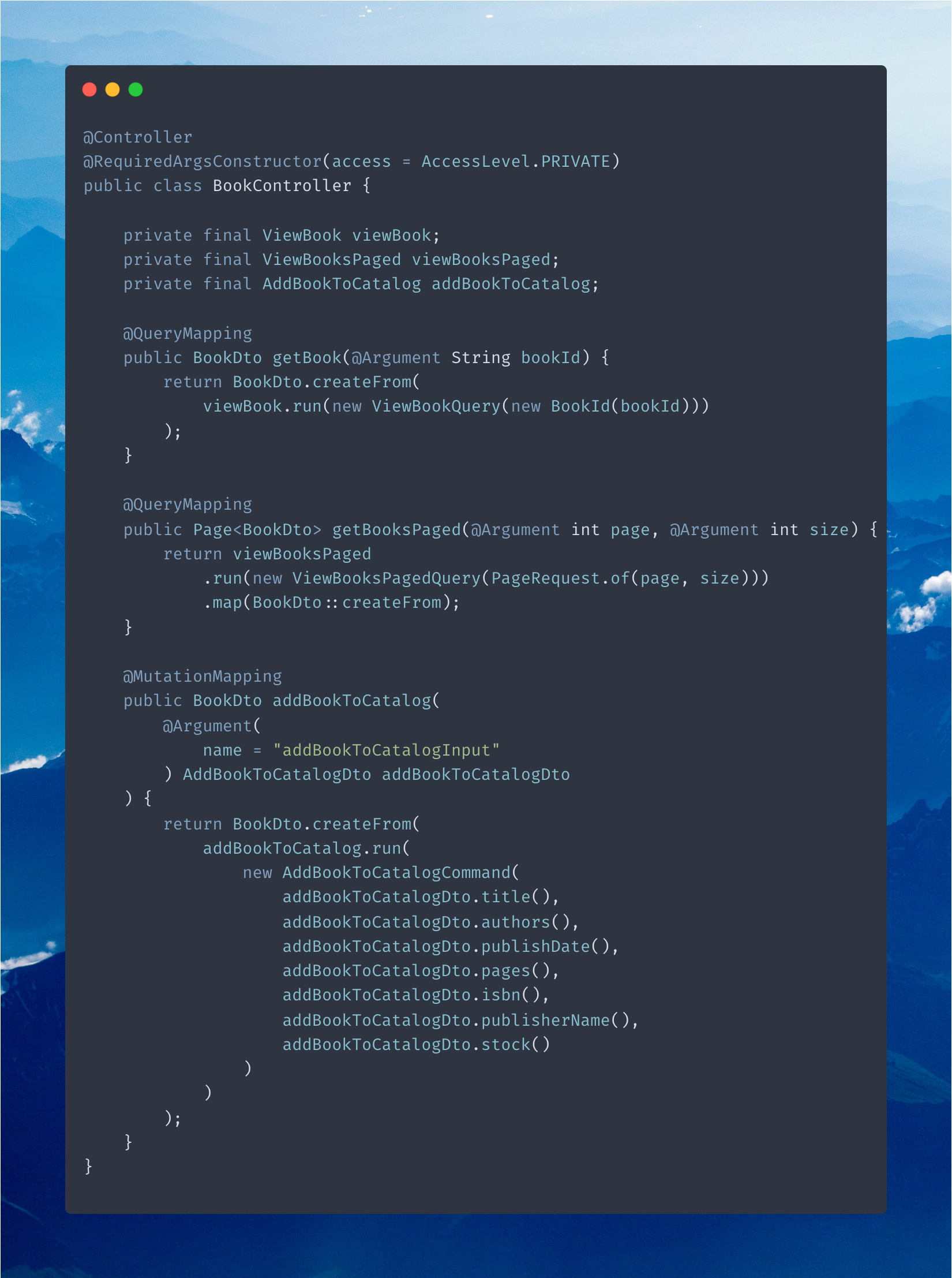
Error Handling
You can achieve exception handling similar to what REST APIs offer with @ControllerAdvice. For that you need to create a component that implements DataFetcherExceptionResolver and check the type of exceptions before you pass it to the client.
Implementation of Services
We have Services or Use Cases like ViewOrder, PlaceOrder, and CancelOrder in our Controller. We organized the software of our Spring Boot app using the Ports and Adapters architecture.
This architecture is a proven pattern designed for loose coupling. Ports define an abstract API that an adapter will implement. Drivers, such as the User through a UI, and adapters funnel into the domain and may trigger a database update through a driven adapter. For example, you could replace the current database with a new one by implementing a new adapter, without requiring changes in the domain.


This architecture provides flexibility, allowing for easy changes in the implementation of our ports. It aligns well with the separation of Commands and Queries and improves testability. Our incoming ports are implemented in the application package and used in the API user interface.

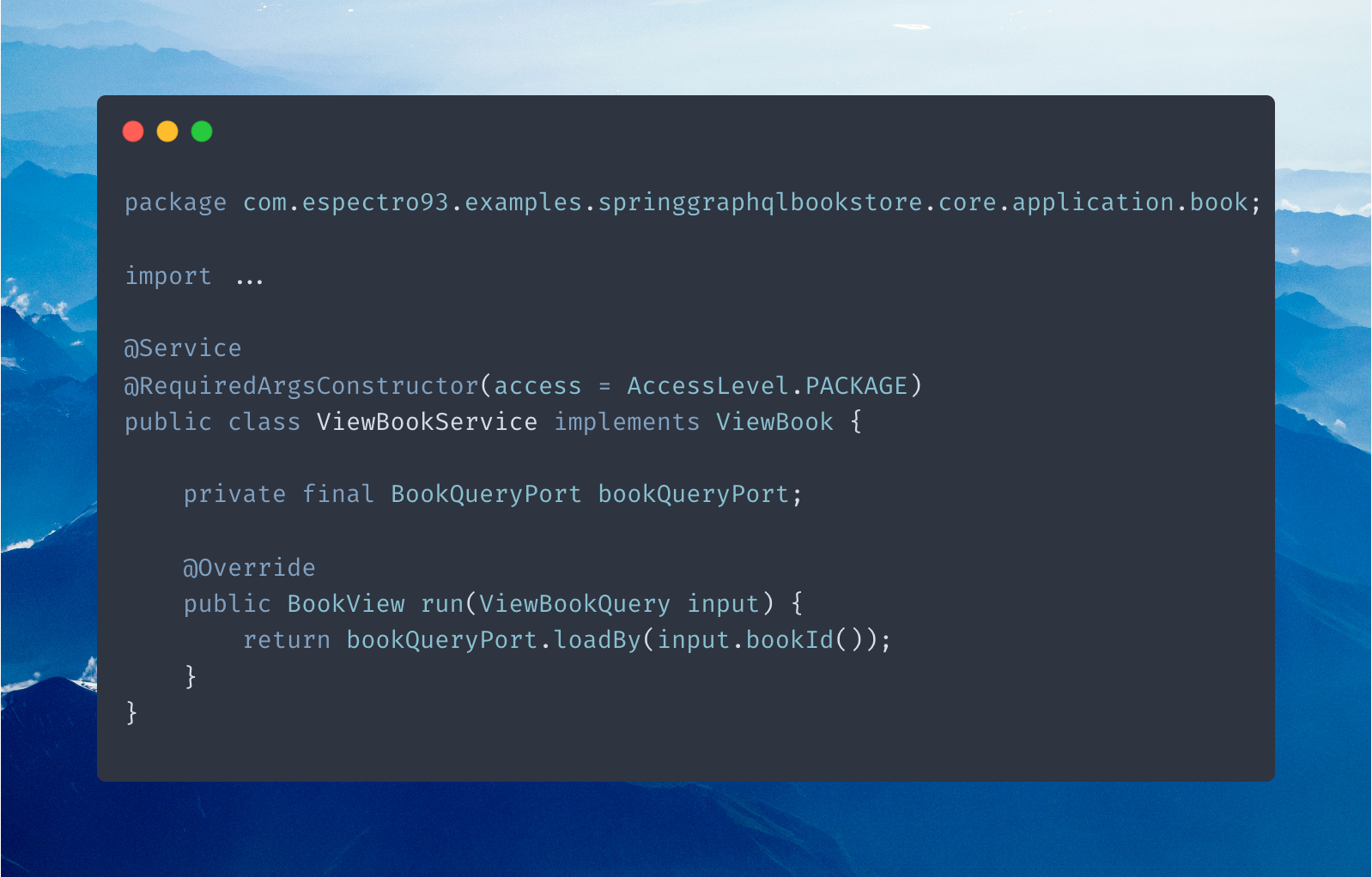
The outgoing ports are implemented in the infrastructure package and used in the application package.


This allows for easy isolation of our domain package and simplifies unit testing. Integration with external systems is also straightforward, as you only need to change the ports or adapters.
However, there is a steeper learning curve and increased complexity since we likely have to write more code. The separation of Aggregates and Persistence requires more effort but can offer better scalability, whereas not separating might provide faster development speed. It is a tradeoff to consider. Traditionally, with a separate team of database developers, it might have made more sense to split and develop independently, but this may not be the case anymore.
Whether you should choose such an architecture depends on your specific needs. For a simple CRUD application, it may not be worth implementing. However, for more complex applications with many external systems, it can be a good fit.
🎬 Bookstore API in Action
In this chapter, we use GraphQL Mutations and Queries to demonstrate the functionality of the bookstore application. All the resources are as CURLs in the linked repository if you are interested. We start by adding a book to the catalog, showing how event replication for the query side creates a query view for that book. Then, we place an order for that book and observe how this reflects on the order view.

🏁 Conclusion
Benefits:
GraphQL is well-supported with Spring and integrates easily with the existing Spring web framework.
Flexible queries and fetching exactly what is needed reduces traffic and improves efficiency.
A single endpoint abstracts away some complexity, although the client must handle payloads for specific queries and mutations.
Drawbacks:
Steeper learning curve for developers.
More complex caching and potential performance trade-offs with overly complex queries.
For more details, see this article.
In general, there are many situations where GraphQL is a good fit. However, you should carefully design your schemas and follow best practices.
🔁 Recap of Series
We began by outlining a bookstore application that is event-driven and uses a CQRS architecture. We established a baseline by implementing messaging features with ActiveMQ and JMS, exploring reliable transactions and messaging with the transactional outbox pattern. We then demonstrated how to integrate Couchbase with Spring Data and perform migrations. This article concludes the series by showing how to consume the API and generate events.
As this was more of a concept, topics like security and authorization were not the focus. The chosen architecture supports good testability, though the repository does not contain many tests. These subjects might be covered in follow-up articles.
I hope you enjoyed reading the series and feel encouraged to try these concepts on your own.
Thanks for sharing @Vu Pham, appreciate it! :)